- Информация о материале
- Создано: 28 марта 2018
Вот сейчас по интернету гуляет ссылка на статью на сайте Радио «Свобода» с доказательствами подтасовок на последних выборах Путина. Вот эта статья, называется «Статистика показывает: за Путина вброшено 10 миллионов бюллетеней».
Все перепощивают, многозначительно и удовлетворенно делают многозначительные физиономии: «Ну вот вам и доказательства!»
А чего доказательства-то? Того, что выборы нечестные?
Да полно-те, будто вы этого и раньше, без статьи этого не знали.
Цель этой статьи, дорогие мои, вовсе не в том, чтобы дать вам доказательства нечестности выборов, а совсем наоборот, в том, чтобы убедить вас в том, что Путин победил по-настоящему, безо всяких фальсификаций.
Я в общем-то далек от мысли о том, что редакция «Свободы» решила сознательно поманипулировать вашим сознанием. Ей принесли статью, доказывающую манипуляции на выборах путина, она с радостью опубликовала. Любое бы оппозиционное издание опубликовало бы такую статью.
В конце-концов, журналисты не математики, и не обязаны замечать математические подвохи.
А в чём там подвох спросите?
Прочтите эту статью. Ничего не заметили странного?
ОК! Внимательно следим за руками.
На выходе из этой статьи мы остаемся с тремя тезисами.
- Выборы были сфальсифицированы, Путину приписали 10 миллионов голосов — вот вам убедительное математическое доказательство.
- Но даже если бы выборы не были сфальсифицированы, то Путин все равно бы победил с большим отрывом. Только тогда бы у него было бы не 73, а 62 процента голосов — всё равно убедительная победа — вот вам математическое доказательство.
- Несмотря на вбросы — это были самые честные выборы путинской эпохи, вбрасывалось бюллетеней меньше, чем раньше, — вот вам математическое доказательство.
Еще не поняли, в чем подвох?
То, что выборы сфальсифицированы — это вы и без того знали, безо всяких графиков. Так что этот пункт можно опустить. Так что в сухом остатке мы имеем только два пункта: «Путин всё равно бы победил безо всяких фальсификаций» и «Это были самые честные выборы путинской эпохи».
Вот ради этих двух пунктов вас и заставили прочесть статью, вбросив первый пункт в качестве заманухи.
— А что, разве не так? — спросите вы, — вот ведь доказательства: графики, математические выкладки…
Ну, давайте говорить, откровенно. Положа руку на сердце, согласитесь, вы ведь на самом деле ни хрена в этих математических выкладках не поняли, вы же никакой не математик, и что такое бином Ньютона уже успели позабыть после школы. И о том, как следует трактовать эти графики со штриховкой вы знаете лишь со слов человека, о котором только что услышали впервые в жизни, будь он хоть трижды математиком.
Это — первое! А второе — и это куда как существеннее, все эти математические трактовки и расшифровки графиков, они имеют смысл лишь тогда, когда данные, на которых строятся эти графики — реальные. Пусть и сфальсифицированные, но — реальные, то есть действительно получены путем подсчета бюллетеней, неважно каких, настоящих или вброшенных.
А вот если эти данные, на которых строились графики, никакого отношения к подсчету бюллетеней не имеют, и были просто произвольно нарисованы с потолка, то очевидно, что и анализировать эти цифирки на предмет возможного вброса бюллетеней нет никакого смысла.
Не надо быть математиком, чтобы сделать это несложное заключение.
Ну согласитесь, бесполезно анализировать результаты выборов на предмет «а был ли вброс бюллетеней», не убедившись предварительно, что цифирки, которые вы анализируете, и на самом деле представляют собой результат подсчета бюллетеней, а не произвольную фантазию избиркома.
Так почему тогда автор статьи этого не сделал?
Странно, правда?
Ну что ж, раз автор статьи в «Свободе» этого не сделал, давайте мы с вами это сделаем. Тем более, что тут всё настолько просто, что можно обойтись и без высшей математики. Достаточно арифметических знаний средней школы.
Но для начала проясним одну важную деталь.
На самом деле проверить результаты подсчетов бюллетеней не просто, а очень просто. Ведь у каждого члена участковой комиссии, в каждого наблюдателя есть копия протокола подсчета голосов на его избирательном участке. И достаточно лишь сверить данные своего протокола с опубликованными данными по участкам — и все сразу станет ясно.
И вот тут — полный облом! Данные по избирательным участкам засекречены! Центризбирком открыто публикует данные подсчета голосов по субъектам федерации, а вот данные по избирательным участкам вы не можете получить ни при каких обстоятельствах. Еще раз, по слогам, они за-сек-ре-че-ны! Не официально засекречны, конечно, но фактически. В природе не существует никаких работающих способов ознакомиться с этими данными.
Единственная информация, при помощи которой можно разоблачить фальсификацию данных — засекречена избиркомом. Наводит на определенные мысли, не так ли?
Ну да ладно, избирком не хочет нам сказать, сами узнаем. Для этого у нас есть чудесные математические методы. Ну, например, методы, позволяющие отличить настоящую случайную последовательность чисел от придуманной человеком.
Подробно я об этом писал месяц назад, так что отсылаю вас к той своей статье. Для тех, кому лень читать, просто скажу вкратце. Любая по-настоящему случайная последовательность чисел подчиняется строгим математическим закономерностям, а человек, который пишет цифры от балды, не может учесть все эти закономерности (их слишком много) и на этом прокалывается.
Так вот, результаты выборов тем замечательны, что с точки зрения математики представляют собой ту самую случайную последовательность цифр. Во всяком случае — должны представлять.
Идем на сайт избиркома и смотрим таблицу выборов по субъектам федерации.
Тут есть два вида данных — количество проголосовавших за каждого из кандидатов, и процент полученных голосов. Одно зависит от другого. Процент от количества, а количество от процента. Следовательно, если наша цель подделать, то подделать получится только что-то одно. Одновременно оба вида данных нарисовать произвольно нельзя.
Поскольку конечным результатом выборов является процент полученных голосов, то если у нас есть цель сфальсифицировать результаты, логичнее будет сразу рисовать нужные проценты и уже на их основе вычислять соответствующее количество голосов.
Вот и проверим.
Не мудрствуем лукаво и используем метод проверки «нарисованности данных», предложенный математиком Константином Кнопом (я упоминал его в прошлой публикации). Он хорош тем, что для его понимания не требуется знания высшей математики, достаточно и школьного курса.
Суть метода проста — проверяем только первую циферку после запятой в десятичной дроби процента. Поскольку эти десятичные дроби получаются делением произвольных чисел (каковым является число проголосовавших), то и первая циферка после запятой будет числом случайным. На этой позиции с равной вероятностью может оказаться любая цифра, от 0 до 9.
А значит, если у нас в таблице избиркома всего 704 дробных числа, то и каждая цифра на первой позиции после запятой должна встречаться с равной частотой. Примерно по 70 нулей, единиц, двоек и т.д., вплоть до девяток.
Это если всё по-честному, и подсчет процент голосов и в самом деле производился путем деления количества проголосовавших (в данном случае даже неважно каких, настоящих или поддельных).
А вот если эти дроби не считались, а сочинялись, то циферки подгонялись под нужные результаты и «сочинители» меньше всего заботились о правильной частотности цифр на первой позиции. Они, скорее всего даже не подозревали, что надо об этом заботится.
Итак, считаем:
|
Цифра |
Сколько раз встречается |
|
0 |
50 |
|
1 |
42 |
|
2 |
60 |
|
3 |
66 |
|
4 |
59 |
|
5 |
98 |
|
6 |
128 |
|
7 |
90 |
|
8 |
64 |
|
9 |
47 |
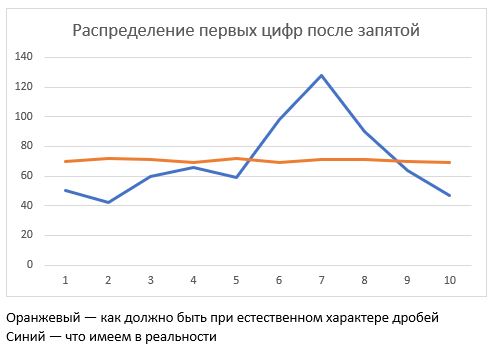
Как видим, распределение циферок совсем не то, какое должно быть при естественном подсчете процентов. Разброс значений в правой колонке должен быть небольшим, ну процентов десять, ну двадцать максимум.
А у нас шестерка встречается в три раза чаще, чем единица.
Кстати, знаете ли вы, что есть такой психологический феномен, часто используемый иллюзионистами: человек, на подсознательном уровне, отдает предпочтение «средним» числам из диапазона от 0 до 9, и склонен игнорировать крайние. Если любого человека (кто не в теме) попросить написать сто произвольных цифр, то в сочиненной им последовательности пятерок, шестерок и семерок будет заметно больше, чем нулей или девяток. А теперь гляньте на нашу табличку.
Вывод напрашивается сам собой.
Все эти проценты, полученные на выборах кандидатами в президенты — они просто нарисованы, а не подсчитаны.
И значит любой дальнейший анализ этих данных в качестве реальных результатов — бессмыслен. Эти числа вообще никак не связаны с тем, как люди голосовали на участках. Любой более глубокий анализ, подобный тому, который приведен в статье «Свободы» покажет лишь, неестественный, фальшивый характер чисел, а вот проанализировать сколько «лишних» бюллетеней было вброшено — это увы. Просто потому, что эти числа никак с бюллетенями не связаны.
Вопрос, а можно ли математическим путем точно узнать, сколько реально голосов было подано за Путина? Очевидно, что нет, потому что, еще раз повторю, опубликованные данные — они вообще никак не связаны с реальным подсчетом бюллетеней.
Но можно догадаться, что будь реальное количество голосов действительно 60% с лишним процентов или даже хотя бы больше 50-ти, то никто бы не пошел на такой большой риск (а это действительно гигантский риск), как перенос фальсификации на уровень Центризбиркома с уровня местных избирательных участков.
Потому что фальсификацию за счет вброса на участке всегда можно списать на местных дурков и даже показательно выпороть их, если вскроется. А вот фальсификация на уровне Центризбиркома - это уже полноценный захват власти и государственный переворот. С чем, мы сейчас, собственно и имеем дело.
Несколько ответов на вопросы, которые, возможно, возникнут у читателей.
Вопрос: Почему вы не взяли для анализа целую часть дроби, а ограничились только дробной частью?
Ответ: Первая значащая цифра большинства естественных величин не является случайным числом. Это математический факт. Особенно это касается выборов. Тот факт, что кто-то из кандидатов наберет процент девяносто с чем-то голосов — он в общем-то ничтожен. Тот факт, что непопулярный кандидат будет набирать только ноль с чем-то процентов голосов — он практически 100%. Так что целая часть дроби, очевидно, случайному закону не подчиняется. А вот дробная часть — да.
Вопрос: Почему вы взяли для анализа только первую цифру после запятой, а не всю дробную часть? Нет ли тут подтасовки с вашей стороны?
Ответ: Вы можете сами провести проверку частотности цифр в целой дробной части. Результат будет тем же, но не столь выраженным. Разброс будет не в три раза, а в два, что тоже далеко за границами нормы. Первые цифирки были взяты исходя их тех соображений, что они являются наиболее значащими, вносят наибольшее влияние на конечный результат, а значит их и имело смысл подделывать в первую очередь. Вторую значащую цифру подделывать уже нет смысла, ее влияние в десять раз меньше.
Вопрос: А если проанализировать не процент голосов, а само число голосов?
Ответ: Если применить к этим числам тот же самый метод «подсчета частотности цифирок», что мы применили для процентов голосов, то эти числа будут выглядеть, как нормальные случайные числа. Но не потому, что они «правильные», а потому что были вычислены исходя из нарисованных процентов. Для «вычисленных» чисел характерно как раз такое превдослучайное распределение цифр. Но поскольку эти числа были вычислены исходя из придуманных процентов, то для них должно быть характерно распределение, отклоняющееся от типичной статистической картины. И такое отклонение — имеет место быть. О чем, собственно и написано в статье на сайте «Свободы», с которой мы начали наш разговор.